In order to see patterns we must choose a single representation (character encoding) to use when viewing our data. This allows us to have a consistent view into the data. If we jump from character encoding to character encoding at will it changes how the data is displayed. This may be a minute change in how the data is displayed or one which would make us miss a pattern. For example, below are several images of different character encodings used to display the same file.
Image: Displayed using ISO Arabic Encoding.
Image: Displayed using ISO Cyrillic Encoding
Image: Displayed using ISO Latin 9 Encoding
If you had a peek at the hex (in the middle section) you would have seen "FF D8" as the first two bytes of the file. If you guessed that was the signature for a JPEG image you would be right.
Looking at the hex is still a pain, you see a lot of pairs and groupings; and after a while your eyes want to wander over the the encoded text representation side on the right. Once your eyes gets to the text side, little islands of calm appears. These islands are regions caused by printable and unprintable characters. If you reference the ASCII chart below, the thirty-two cells highlighted in brown represent unprintable characters. These include such items formatting characters (tabs, carriage returns, line-feeds, ...) and legacy characters which typically are not used in modern computing.
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
0
|
NUL
|
DLE
|
SP
|
0
|
@
|
P
|
`
|
p
|
1
|
SOX
|
DC1
|
!
|
1
|
A
|
Q
|
a
|
q
|
2
|
STX
|
DC2
|
“
|
2
|
B
|
R
|
b
|
r
|
3
|
ETX
|
DC3
|
#
|
3
|
C
|
S
|
c
|
s
|
4
|
EOT
|
DC4
|
$
|
4
|
D
|
T
|
d
|
t
|
5
|
ENQ
|
NAK
|
%
|
5
|
E
|
U
|
e
|
u
|
6
|
ACK
|
SYN
|
&
|
6
|
F
|
V
|
f
|
v
|
7
|
BEL
|
ETB
|
^
|
7
|
G
|
W
|
g
|
w
|
8
|
BS
|
CAN
|
‘
|
8
|
H
|
X
|
h
|
x
|
9
|
HT
|
EM
|
(
|
9
|
I
|
Y
|
i
|
y
|
A
|
LF
|
SUB
|
)
|
:
|
J
|
Z
|
j
|
z
|
B
|
VT
|
ESC
|
*
|
;
|
K
|
[
|
k
|
{
|
C
|
FF
|
FS
|
+,
|
<
|
L
|
\
|
l
|
|
|
D
|
CR
|
GS
|
-
|
=
|
M
|
]
|
m
|
}
|
E
|
SO
|
RS
|
.
|
>
|
N
|
^
|
n
|
~
|
F
|
SI
|
US
|
/
|
?
|
O
|
_
|
o
|
DEL
|
These unprintable characters are typically represented by forensic applications by a dot, or whitespace, or some other standardized character.
The Short of it...
- There are many character encodings out there, but to view your data I would recommend selecting one.
- You can change your encoding settings as needed, but default back to the one you selected.
Which one you ask?
Well I've stuck with "ISO/IEC 8859-15, also known as "Part 15: Latin alphabet No. 9". Which I like to call "Latin ISO 9" or various combinations of the same. Why this one? Well, when I was a newly hatched script monkey mashing buttons it was said to me that this was the one to use. Now since a I no longer drag my knuckles, and rarely scratch myself I can give you my reasoning for continuing to use it.
- It is an 8 bit (1 byte) fixed length encoding scheme. In short, one byte is equal to one character. This means n bytes of data no matter how it is arranged is displayed as n characters.
- The encoding is based on ASCII, so at least for the English language and a numerous Latin alphabet derivative languages it works in whole or part.
- The encoding supports Western European languages. Yes this statement would appear to be awfully European/English centric, but I assure you it doesn't matter as much as you think.
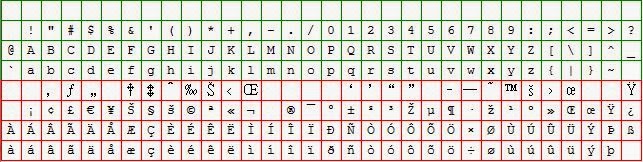
So let's look at Latin ISO 9 ... I won't give you the historic details, just the pretty pictures. Remember this series is on visualizing patterns, not lecturing on the evolution of computing.
Image: Latin ISO 9
If we can can believe Wikipedia the following languages are supported under Latin ISO 9.
Afrikaans, Albanian, Breton,
Catalan, Danish, Dutch, English, Estonian, Faroese, Finnish, French, Galician,
German, Icelandic, Irish, Italian, Kurdish, Latin, Luxenbourgish, Malay,
Norwegian.
Using Wikipedia again, I came up with an approximate coverage of .. cough .. 2.5 billion primary and secondary speakers for the above languages. taken with a large grain of salt the coverage comes out to what you see roughly below.
The countries in green are those I could identify which either had a language based on the above list as an official language, but this does not necessary mean it's a primary or majority language. Not data I would make a scholarly publication on, but good enough if you squint. Keep in mind that the top half of North America (Alaska /Canada), Greenland, and Australia have a really low population density, but it looks great in the picture. Also,some of the countries identified in green have than one language being utilized internally, especially Africa and India.
Examples:
Morocco has Arabic as the official language, but French is very common. Signage within the country typically has both Arabic and French wording. It’s also worth noting, that besides the Arabic and French, the Berber language is also found within Morocco (Tifinagh alphabet).
India has Hindi and English for official languages, but has an additional 20 other regional languages are in use within the country. Hindi along with a large number of these regional languages has their own character sets.
So let’s go over what languages this encoding does not cover.
• Chinese and Japanese Ideographs
• Korean Ideographs (Hangul)
• Cyrillic
• South/Southeast Asian Scripts
• Arabic
• Hebrew
• Berber
• Amharic
• et al…
This is the point where you say loudly, "of cooooourse they are not supported. They are not Western European languages'.
To this I reply, you are absolutely correct, but it doesn't affect our ability to identify patterns. I'll get to that in an upcoming post ..
Your take away points:
- Choose an encoding.
- Return to that view when you do not have to be specifically view data in another character encoding scheme.
- I like ISO Latin 9, but as I wrote this I realized that was because I have the bias of being able to recognize the characters in the patterns. For example the first set of three images in this post are of a JPEG. When I see I JPEG (in ISO Latin 9) I see "YoYa" as the first two bytes, but if I was Cyrillic reader the Cyrillic may be a better choice.
If you have a better Encoding scheme you like to use, drop me a line with your reasoning. I'm always ready to learn new tricks.
to be continued ....